Squser>>allSqweets
“returns messages from self and friends”
| allsqweets |
allsqweets := SortedCollection sortBlock: [ :a :b | a timestamp < b timestamp ].
allsqweets addAll: self messages.
myFriends do: [ :each | allsqweets addAll: each messages ].
^ allsqweets
———————-
allSqweets is a simple 4 line method, but delivers the core feature of Twitter: displaying a timeline of all a user’s and his friends’ messages. And thus started my exploration into Seaside, a Smalltalk framework for developing web applications.
I started playing around with Seaside last year, but time constraints prevented me from getting too far. But, I’m at it again. This latest burst of energy was in part generated by the “fail whale” of Twitter. Prompted by friends, I started using Twitter a lot from the early part of this year. Pretty cool, simple application, yet, why does it keep crashing? Hey, though, it’s got a million users, so give it a break.
A more perplexing problem, to me at least, was the linking of replies. Or the lack of said linking. I click “reply” to someone’s twitter, post my reply. There’s even a link on my posting “in reply to …”. Click on it, and more times than not, it would link back to some other message, not the message I was replying to. What’s up with that? It got me thinking: conceptually, Twitter is a really simple application: what would it look like in Smalltalk? Not trying to solve performance problems or scalability or anything real like that, but simply as a pure object exercise, just what would Twitter look like in Smalltalk?
I’ve been looking around for other web frameworks to develop in. That’s why I’ve given Seaside a serious look. On the prompting of other friends, I recently gave Ruby on Rails a look, and earlier had glanced over at Django. Both, surprisingly, kind of gave me the shudders: pop in some code for your initial objects, and they auto-generate lots of code for you. All code broken down into a clean separation of concerns: model files here (class definitions), view files there (web templates), controllers over there. Nice, but now I’ve got lot’s of files, and I’ve got to navigate my way around to figure out what to modify where. I’m sure once you get used to it, it’s easy to remember what directory has what files, but I’m impatient you see, and don’t have much spare time (see above).
All these files reminded me of my C development days, with scores of header files (.h), code files (.c), and my own make files, etc. I’m not knocking these frameworks on the Ruby or Python languages – long ago, I learned that language wars are useless. But, maybe it’s just my aesthetic: I’ve always found Smalltalk super clean and easy to read and navigate, and it remains my fastest development language. So, yeah, maybe Ruby and Python are “Rapid-Enough” Application Development environments, compared to, say Java or Visual Basic, but I yearn for truly Rapid Application Development again.
Then came Barcamp Houston. Kind of creeped up on me. It wasn’t til the morning of the conference when I suddenly got inspired: I should present something here! But, a late start to the day, and an already depleted laptop battery proved challenges for preparing any kind of presentation, much less something that wouldn’t embarress me. I would need to spend a little time relearning the Seaside environment (which has undergone a few point releases since last year), and thinking through an application.
Then my thoughts went back to the Twitter applicaiton. Wouldn’t that be a simple application to demonstrate within Seaside? And sure enough, it was been: in fact, too simple to demonstrate some of Seaside’s more powerful features (like tasks and workflow – the real meat of “continuations”). Nevertheless, a good test case to begin.
So, I still don’t have much time in my busy schedule, what with my own projects, my business, family, assisting in the launching of my wife’s new restaurant, etc., but I have been able to squeeze in a few hours here and there to develop Sqwitter, an implementation of Twitter in Squeak and Seaside. The next several blog postings will walk through my development of Sqwitter, and should serve as a useful tutorial for Seaside (there are already some excellent tutorials on the web, and a book too). When I finish the code, I’ll also roll the application out to a demonstration website for readers to play.
Next: Sqwitter objects and Seaside components.
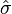 , μ - LSL / 3 *
, μ - LSL / 3 *