As mentioned earlier, I’ve been involved in client’s Production Reporting application project, when the subject of Cpk came up. After a lot of inconsistent references to the statistic and lot’s of code that approximated but didn’t exactly calculate it, I finally discovered the proper formula for Cpk. Here it is:
Cpk = min ( USL - μ / 3 * 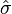 , μ - LSL / 3 * )
, μ - LSL / 3 * )
Where USL is the Upper Specification Limit, LSL is the Lower Specification Limit, μ is the arithmetic mean of the results and , sigma hat, is the estimated standard deviation (sigma hat is going to turn out to be the kicker in this equation).
Let’s say you have a product you have to make that must be within some specifications: like, the length of a sub sandwich. It should always be 12″ long, but it’s acceptable if the final sandwich comes out between 11″ (LSL) and 13″ (USL). Cpk is the minimum of either the average deviation from the upper limit divided by 3 times the estimated standard deviation, or the average deviation from the lower limit divided by 3 times the standard deviation.
All this would be easy to calculate using SQL if just plain ole standard deviation were involved. However, using standard deviation instead of estimated standard deviation (sigma vs. sigma hat), and you have the equation for Ppk, a different statistic. Always one to be lazy, I ask our client: “would it be okay to report just the Ppk statistic?” Of course, the answer was no!
So, I had to figure out how to compute sigma hat. And, I wanted to do this exclusively in SQL. Surprisingly, in my many searches on the Internet, I wasn’t able to find any example code to accomplish this. Hence my reason for writing this posting. I’ve solved the problem in SQL (at least to my satisfaction), and want to share my results with the world.
Doing a little research, I discovered sigma hat, that is, estimated standard deviation, was created a little before computers were popular and the statistic had to be hand computed on the field. It’s an interesting measure, though, as it measures the variation between successive measures of the process results, instead of the overall standard deviation. In a nutshell, it tells you how much a process is varying step by step. If one sandwich were 12.5″, the next 11.5″, then back to 12.5″, the standard deviation would be rather low, but many manufacturers would agree that it’s not really a good process – it would be better if the maker were hitting consistently off target than skipping around so much. For example, if it were making sandwiches 11.5″ consistently, machine could be adjusted to get it closer to the target 12″ value. If it’s skipping around so much, something unpredictable is happening. Statistically, regular standard deviation would hide this situation, while estimated standard deviation would perhaps highlight a problem.
The formula for sigma hat is:
= R-bar / d2
where R-bar is the average ‘moving range’ of the results, and d2 is a constant, depending on the size of the data range chosen. Many process control statistics books will publish a chart of d2 constants, in a table from range sizes (I like to say “bucket sizes”) from 2 to 20.
So, for example, let’s say you have a sample of 20 sandwiches made in your sandwich machine, and you have all the lengths measured. It’s important that you get these measures in the order of the sandwiches made. To compute the moving range, break your 20 measures up into buckets of a fixed size; for example, if your bucket size were 10, you’d just have 2 buckets of data: the first 10 results, then the next 10 results; with a bucket size of 5, you’ll have 4 buckets, etc. The moving range is just the difference between the highest and lowest values in that bucket. R-bar is the average of all your bucket’s “moving ranges”. Divide that average by the d2 constant, and you have sigma hat.
Easy on paper – a wee bit of a challenge in SQL. A single SELECT statement just won’t cut it. Since this involves looking at data in sequence, I had to violate my normal SQL-programming rule: “CURSORs considered Evil”. This is a perfect example for the proper use of cursors (I’ll rant about the misuse of cursors later).
So, here’s how I did it. First, I needed a stored procedure to compute sigma hat (the code here is using Microsoft SQL Server; exact code may be a bit different in other SQL dialects).
CREATE PROCEDURE calculateSigmaHat
@testname varchar(50),
@bucketsize tinyint
AS
BEGIN
DECLARE
@result as decimal(18,6),
@range as decimal(18,6),
@count as integer,
@rangebucket as decimal(18,6),
@bucketcount as integer,
@sigmahat as decimal(18,6) CREATE table #bucket (result decimal(18,6))
DECLARE Sigmarator cursor local for
SELECT result
from testresults
where testname = @testname
order by testdatetime
OPEN Sigmarator
FETCH next from Sigmarator
into @result
SELECT @bucketcount = 1
SELECT @count = 0
SELECT @rangebucket = 0
WHILE @@fetch_status = 0
BEGIN
INSERT into #bucket values(@result)
IF @bucketcount = @bucketsize
BEGIN
SELECT @range = MAX(result)-MIN(result)
from #bucket
SELECT @count = @count + 1
SELECT @rangebucket = @rangebucket + @range
SELECT @bucketcount = 0 --reset for the next group
TRUNCATE TABLE #subgroup
END
FETCH next from Sigmarator
into @result
SELECT @bucketcount = @bucketcount + 1
END
CLOSE Sigmarator
SELECT @sigmahat =
CASE WHEN @count = 0 THEN 0
ELSE (@rangebucket/@count) / d2
END
from statchart
where n = @subgroupsize
DROP table #bucket
INSERT INTO #sigmahatresult VALUES(@sigmahat)
END
This assumes that test results are in a table called testresults, with 3 columns: testname, testdatetime, and result. You’ll also need another table called statchart, with 2 columns, n and d2. This table should be prefilled with the d2 constants:
| n | d2 |
|---|---|
| 2 | 1.128 |
| 3 | 1.693 |
| 4 | 2.059 |
| 5 | 2.326 |
| etc. |
Since this stored procedure uses a temp table, I couldn’t program this as a Function. Thus, I had to resort to passing the result of this stored procedure via a temporary table, sigmahatresult (note: I won’t vouch for this procedure being thread-safe. I’ll let that be an exercise for the reader).
What’s the appropriate bucket size to use? I don’t know: I think that requires some experimentation, or the specific factory process may dictate an appropriate bucket size. My client used 2, so that’s what I went with; this stored procedure, though, works with any bucket size desired (caveat: I haven’t fully tested this code for certain limit conditions)
CalculateSigmahat and sigmahatresult is used within the following stored procedure:
CREATE PROCEDURE calculateCpk
@testname
@bucketsize tinyint
AS
BEGIN
declare @test varchar(50),
@sigmahat decimal(18,6)
CREATE TABLE #sigmahatresult (result decimal(18,6))
DELETE FROM cpkresults
EXEC calculateSigmaHat @testname,@bucketsize
SELECT @sigmahat = result
from #sigmahatresult
TRUNCATE TABLE #sigmahatresult
INSERT INTO CpkResults (testname,cpk,ppk)
SELECT @plant,@grade,@test,
CASE WHEN (upper - avg(result)) / (3 * @sigmahat) < (avg(result) - lower) / (3 * @sigmahat)
THEN (upper - avg(result)) / (3 * @sigmahat)
ELSE (avg(result) - lower) / (3 * @sigmahat) END as 'cpk',
CASE WHEN (upper - avg(result)) / (3 * stdev(result)) < (avg(result) - lower) / (3 * stdev(result))
THEN (upper - avg(result)) / (3 * stdev(result))
ELSE (avg(result) - lower) / (3 * stdev(result)) END as 'ppk'
FROM testresults r
JOIN testlimits l
on r.testname = l.testname
WHERE testname = @testname
and @sigmahat != 0
GROUP by upper,lower
DROP TABLE #sigmahatresult
SELECT r.testname,
avg(cpk) as 'avgCpk',sum(cCount) as 'cCount'
from CpkResults r
END
This depends on one more table, testlimits, with 3 columns, testname, upper, and lower, which stores the upper and lower control specifications for the given test. There’s also a prexisting ckpresults table. Again, the way I developed this is probably not thread-safe, but should give readers enough inspiration to develop their own sigmahat and cpk calculations with their specific database design.
So, here you go, the computation of Cpk in SQL, in less than 50 lines of code. Considering the predominance of SQL and relational databases in corporations, I hope the reader will find this a handy solution to their problem if they’re ever involved in calculating six sigma statistics like the ever-popular Cpk. Wear your quality belt proudly 🙂