As mentioned earlier, I’ve been involved in client’s Production Reporting application project, when the subject of Cpk came up. After a lot of inconsistent references to the statistic and lot’s of code that approximated but didn’t exactly calculate it, I finally discovered the proper formula for Cpk. Here it is:
Cpk = min ( USL - μ / 3 * 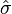 , μ - LSL / 3 * )
, μ - LSL / 3 * )
Where USL is the Upper Specification Limit, LSL is the Lower Specification Limit, μ is the arithmetic mean of the results and , sigma hat, is the estimated standard deviation (sigma hat is going to turn out to be the kicker in this equation).
Let’s say you have a product you have to make that must be within some specifications: like, the length of a sub sandwich. It should always be 12″ long, but it’s acceptable if the final sandwich comes out between 11″ (LSL) and 13″ (USL). Cpk is the minimum of either the average deviation from the upper limit divided by 3 times the estimated standard deviation, or the average deviation from the lower limit divided by 3 times the standard deviation.
All this would be easy to calculate using SQL if just plain ole standard deviation were involved. However, using standard deviation instead of estimated standard deviation (sigma vs. sigma hat), and you have the equation for Ppk, a different statistic. Always one to be lazy, I ask our client: “would it be okay to report just the Ppk statistic?” Of course, the answer was no! Continue reading How to Cpk the SQL Way